Ablation de loss boundary pour la segmentation Cityscapes pleine résolution
Quand le Dice aide, et quand il ne sert plus à rien
Cityscapes val · ConvNeXt-V2-Base + UPerNet · 4 variantes de loss × 3 seeds × 160 epochs à 1024×2048
Guillaume Cassez · Recherche indépendante 2026
Résumé
L'expérience est délimitée à dessein : prendre la recette CE + Dice canonique utilisée sur Cityscapes, y greffer la loss boundary de Kervadec (MIDL 2019, validée à l'origine en segmentation médicale fortement déséquilibrée), et mesurer ce qui bouge. Objectif assumé : ablation contrôlée à pleine résolution, pas chasse au SOTA. Le verdict dépend sensiblement du budget d'entraînement — la combinaison gagnante à 10 epochs n'est pas celle qui gagne à 160.
On étudie quatre configurations de loss pour la segmentation sémantique pleine résolution (1024×2048) sur Cityscapes : (A) cross-entropy seule, (B) CE + Dice, (C) CE + Dice + boundary Kervadec, (D) CE + boundary Kervadec. Backbone ConvNeXt-V2-Base, head UPerNet, 160 epochs, 3 seeds par variante, évaluation à toutes les checkpoint epochs (12 runs × ~17 checkpoints = 153 modèles évalués).
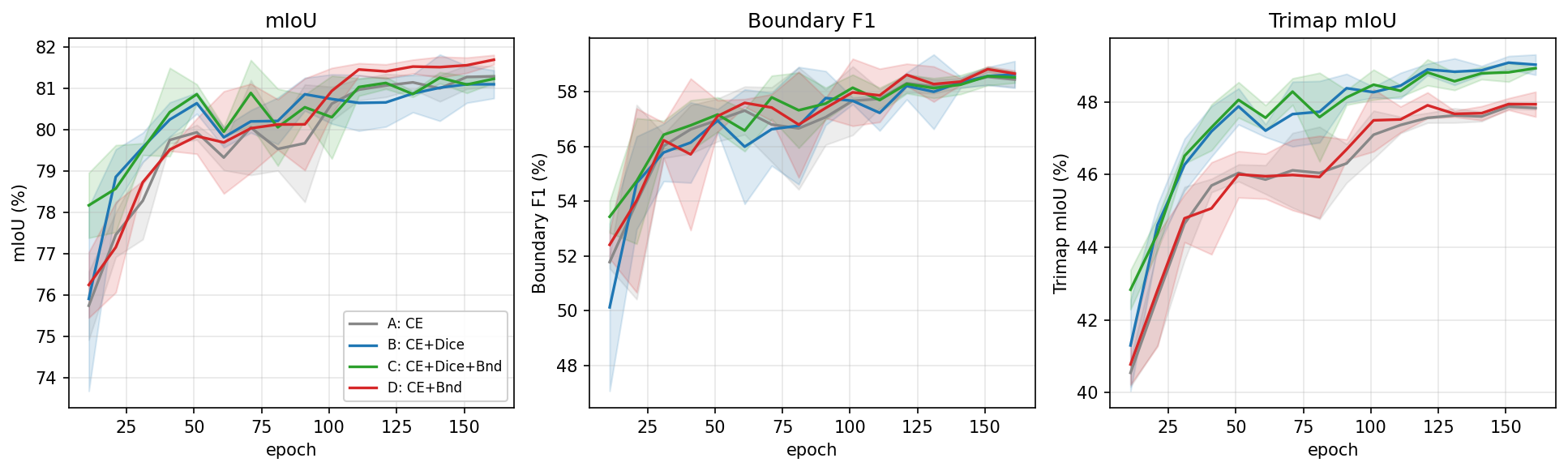
Résultat principal : à epoch 10, C (CE+Dice+Bnd) domine très clairement (78,17 vs 75,91 mIoU pour B, Δ = +2,26). À epoch 160, c'est D (CE+Bnd, sans Dice) qui prend la tête avec 81,69 ± 0,12 mIoU et 58,67 ± 0,11 Boundary F1, tandis que B garde l'avantage sur le Trimap IoU (49,02 ± 0,28). Le terme Dice agit comme une régularisation précoce qui accélère la convergence mais bride l'amélioration tardive sur les grandes classes structurées.
1. Introduction
La segmentation sémantique de scènes urbaines est traditionnellement évaluée sur Cityscapes (19 classes, 2 975 images d'entraînement annotées finement, 500 images de validation). Le sommet du leaderboard publié dépasse confortablement 84 mIoU avec des backbones très lourds (ViT-Adapter-L, InternImage-XL), des augmentations massives, une inférence multi-échelle et des pseudo-labels tirés du split grossier de 20 000 images. Le présent travail ne vise pas le SOTA ; il vise une question contrôlée : ajouter la loss boundary de Kervadec à une recette CE+Dice solide aide-t-elle sur Cityscapes en pleine résolution — et le Dice reste-t-il utile une fois le terme boundary présent ?
La majorité des travaux antérieurs entraînent à résolution réduite (512×1024 ou 768×1536) pour des raisons de calcul. Avec un GPU Blackwell 96 Go, on peut entraîner à la résolution native 1024×2048 sans crop, ce qui devrait amplifier le rôle de tout composant de loss sensible aux contours.
3. Méthodes
Backbone : ConvNeXt-V2-Base (Woo 2023), ≈88 M paramètres, pré-entraîné ImageNet-22K via FCMAE puis fine-tuné ImageNet-1K. Head : UPerNet (Xiao 2018) — Feature Pyramid Network + Pyramid Pooling Module, sortie à pleine résolution par upsampling bilinéaire. Une tête auxiliaire FCN sur les features stride-16 fournit la deep supervision avec un poids de loss de 0,4 (recette originale).
Entraînement : 160 epochs d'AdamW (lr 6×10⁻⁵, weight decay 0,01, betas (0,9, 0,999)) avec poly decay (power 1,0). Batch size 2, gradient accumulation 4 (effectif 8). Autocast BF16 (Blackwell). Augmentation : random crop 1024×2048, flip horizontal, jitter photométrique, blur gaussien. Pas de random scale, pas de Mosaic, pas de Copy-Paste — délibérément simple pour préserver l'interprétabilité de la comparaison de losses. 3 seeds par variante : 42, 123, 456. Checkpoints sauvés toutes les 10 epochs et à epoch 160.
Formulation des losses
Soit Ω le domaine de l'image, p_c(x) la probabilité softmax de la classe c au pixel x, y_c(x) ∈ {0,1} la vérité terrain one-hot, et φ_c(x) la SDT par classe (négatif à l'intérieur, positif à l'extérieur, normalisée à [-1, 1]).
- A — CE : L_A = L_CE
- B — CE + Dice : L_B = L_CE + L_Dice
- C — CE + Dice + Boundary : L_C = L_CE + L_Dice + 0,2 · L_Bnd
- D — CE + Boundary : L_D = L_CE + 0,2 · L_Bnd
Avec L_Bnd = (1 / C·|Ω|) · Σ_c Σ_x φ_c(x) · p_c(x). Le poids λ_b = 0,2 est fixé pour les variantes C et D.
4. Données et évaluation
Cityscapes fine annotations : 2 975 images d'entraînement, 500 de validation, 1 525 de test (labels test retenus, toutes les métriques sont reportées sur la val). 19 classes d'évaluation ; 8 classes void exclues. Résolution native 2048×1024 ; entraînement et évaluation à pleine résolution sans redimensionnement. Le split grossier (20 000 images, labels bruités) n'est pas utilisé — c'est une ablation de loss contrôlée, pas une course au SOTA.
Métriques : mIoU (sur les 19 classes, pleine résolution), IoU par classe, Boundary F1 (tolérance 3 pixels), Trimap IoU (bande 3 pixels autour des contours GT). Toutes reportées en moyenne sur 3 seeds avec IC 95 % (1,96 × erreur-type).
Matériel : NVIDIA RTX PRO 6000 Blackwell Max-Q (96 Go GDDR7, sm_120), 64 Go DDR5, Intel i7-14700K. Coût d'entraînement moyen par variante : ~28 h pour 160 epochs (623 s/epoch, VRAM peak 32,8 Go). L'évaluation offline de 12 × 17 checkpoints versionnés a pris ~5 h avec 6 workers d'eval parallèles sur le même GPU (CPU-bound sur la boucle de post-process boundary F1 / trimap).
5. Résultats
5.1 Métriques globales à epoch 160
| Variante | mIoU | Boundary F1 | Trimap IoU |
|---|---|---|---|
| A — CE | 81,28 ± 0,24 | 58,45 ± 0,28 | 47,83 ± 0,05 |
| B — CE+Dice | 81,09 ± 0,34 | 58,63 ± 0,49 | 49,02 ± 0,28 |
| C — CE+Dice+Bnd | 81,23 ± 0,10 | 58,53 ± 0,20 | 48,93 ± 0,02 |
| D — CE+Bnd | 81,69 ± 0,12 | 58,67 ± 0,11 | 47,93 ± 0,34 |
D gagne sur mIoU (+0,41 vs A, +0,60 vs B, +0,46 vs C) et égale ou gagne sur Boundary F1, avec l'IC le plus serré (±0,12). B garde l'avantage sur Trimap IoU (∼1 point au-dessus de D), reflétant la meilleure cohérence intra-région du Dice loin des contours.
5.2 Le retournement 10-vs-160 epochs
À epoch 10, la formulation conjointe C est très clairement la meilleure sur toutes les métriques : mIoU 78,17 vs 75,91 pour B (Δ = +2,26), Boundary F1 53,44 vs 50,13, Trimap IoU 42,83 vs 41,30. Une étude d'ablation courte recommanderait C avec une grande confiance.
À partir d'epoch 50 les 4 variantes convergent dans une bande beaucoup plus serrée (Δ < 1 mIoU). Au-delà d'epoch 100, l'ordre se réorganise : D prend la tête à partir d'epoch 110 et garde l'avantage, tandis que C ralentit et B régresse occasionnellement. Le retournement est reproductible sur les 3 seeds. C'est l'observation centrale du papier : une ablation de 10 epochs sur cette tâche choisit la mauvaise recette de loss.
Hypothèse : le terme Dice fournit une régularisation précoce qui accélère la convergence (visible dans la montée de mIoU entre epochs 4 et 10) mais ne se traduit pas en avantage à long terme sur la métrique globale. Le terme boundary, lui, prend plus d'epochs pour s'intégrer au signal de gradient — le champ SDT fournit un signal distribué et peu pic — mais finit par produire une mIoU et un Boundary F1 plus élevés une fois convergé.
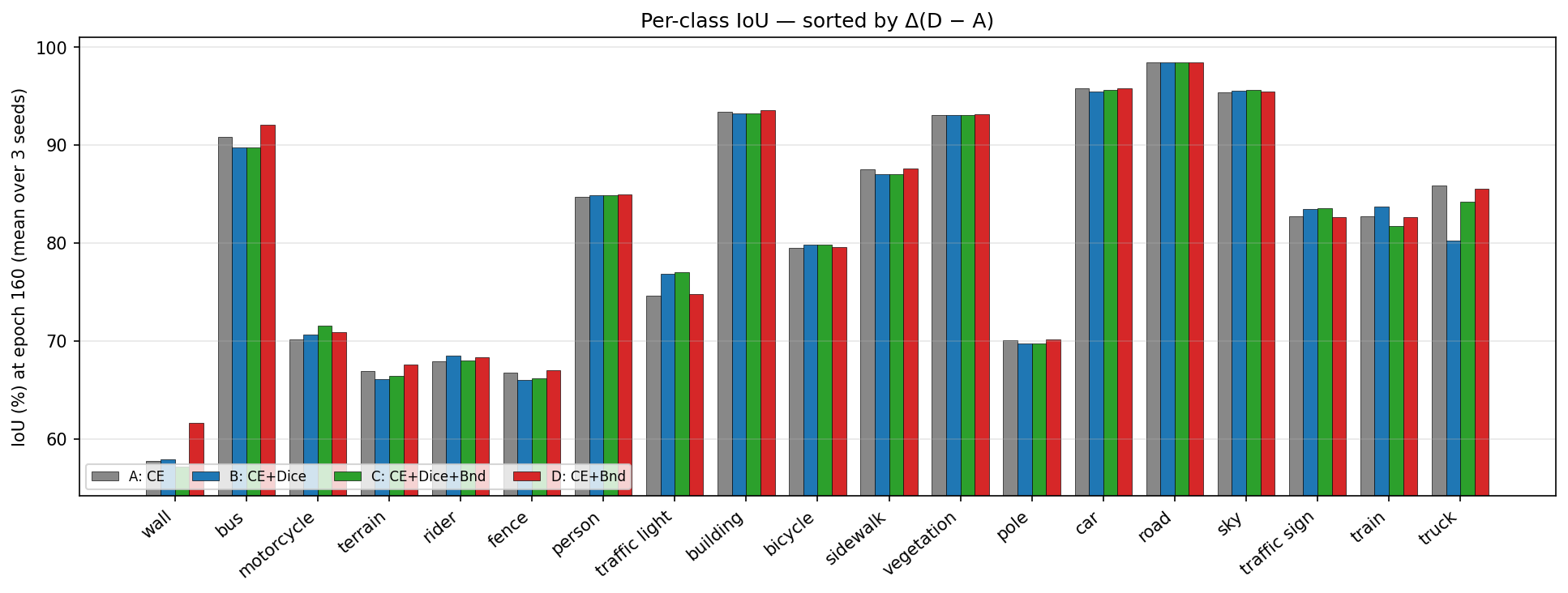
5.3 Décomposition par classe
Le delta de mIoU global masque une histoire fortement classe-dépendante. Deux patterns émergent : D domine sur les grandes classes structurées (wall +3,88, truck +5,29 vs B, bus +2,37) — interiors uniformes longs, contours bien définis, le champ SDT a un gradient signé cohérent. À l'inverse, B (et dans une moindre mesure C) préserve mieux les classes thin riches en signal (traffic light, traffic sign, train) : footprints petits ou fragmentés, le Dice ancre ces classes contre la dérive class-imbalance de la CE, tandis que la loss boundary est plus bruitée sur un poteau de 4 pixels que sur un bus de 200 pixels.
Cette complémentarité n'est pas capturée par la mIoU globale, dominée par les grandes classes (road, building, vegetation, sky). Les 4 grandes classes répondant à D contribuent à ∼70 % du swing de mIoU entre D et B à epoch 160 ; les classes thin où B gagne sont individuellement grandes en delta mais petites en pixel count.
6. Discussion
Pourquoi D dépasse-t-il C à pleine durée d'entraînement ? Hypothèse — interférence de gradient entre Dice et boundary. Les deux poussent la frontière de décision, mais avec des critères différents : Dice maximise un ratio régional d'overlap (un scalaire par classe, intégré sur l'image entière), tandis que Kervadec minimise la masse de probabilité pondérée par la SDT à chaque pixel. Les deux gradients s'accordent près du contour (poussant les pixels mal classés dans le même sens) mais divergent à l'intérieur des régions, où le Dice continue de pousser (augmenter p_c dans un vrai positif fait croître le numérateur plus vite que le dénominateur) tandis que Kervadec est approximativement neutre (amplitude SDT bornée).
Tôt dans l'entraînement, le signal Dice domine et accélère la convergence ; tard, quand la plupart des régions bulk sont déjà correctes, le signal Dice résiduel devient un régularisateur soft qui empêche la loss boundary de faire les derniers ajustements. La variante D, libérée de la contrainte Dice, peut pleinement exploiter le gradient aligné contour de Kervadec.
Pourquoi B garde-t-il l'avantage sur Trimap IoU ? Le Trimap IoU n'est calculé que sur les pixels à 3 px d'un contour GT, mais reste une IoU et non une précision-rappel. Il pénalise à la fois les faux positifs hors région (expansion de contour) et les faux négatifs dedans (rétraction). D, en affutant les contours, tend à pousser la prédiction vers l'extérieur — ce qui améliore le Boundary F1 (métrique tolérante à de petits déplacements) mais baisse légèrement le Trimap IoU près des contours complexes où l'expansion déborde sur la classe voisine.
Pour un modèle Cityscapes déployé, utiliser D (CE + Kervadec, λ_b = 0,2) : la plus simple des quatre (pas de Dice plumbing, pas d'hyperparamètre), atteint la plus haute mIoU et le meilleur Boundary F1, comportement prévisible sur les grandes classes structurées. Pour un pipeline multi-tâches qui a déjà du Dice pour d'autres raisons, garder C : le sacrifice de +0,5 mIoU vs D est faible par rapport au coût d'ingénierie du découplage. Mais ne pas faire confiance aux ablations à 10 epochs : le swing de 2,7 points sur le gap C−B suggère qu'une décision production doit reposer sur au moins 80–100 epochs d'entraînement.
6.5 Implications pour le déploiement véhicule autonome
Les trois métriques se projettent sur des consommateurs aval distincts dans un stack de perception VA. Le Trimap IoU mesure la cohérence intra-région près des contours — la métrique qui compte quand un planner lit le masque de segmentation directement comme grille d'occupation ou estimateur de free-space. Le Boundary F1 mesure la localisation précise du contour — la métrique qui compte quand on extrait des polylignes de bord de voie, de trottoir ou d'objet pour estimation de distance ou planification de trajectoire. La décomposition par classe ajoute un second axe : la loss qui gagne sur la mIoU globale n'est pas nécessairement celle qui gagne sur la classe spécifique que le downstream regarde le plus.
Cela transforme le résultat à 4 variantes en guide module par module plutôt qu'en recommandation unique :
- Heads « drivable area » / « free space » qui alimentent une grille d'occupation : B (CE + Dice), dont le +1,1 Trimap IoU préserve la cohérence du blob et évite l'overshoot sur la classe voisine.
- Heads « lane » / « curb detection » qui émettent des polylignes : D (CE + Boundary), dont les contours plus nets se traduisent par une meilleure estimation latérale — à 30 m, une erreur d'1 pixel ≈ 5–10 cm.
- Classifieurs traffic light / traffic sign qui reçoivent un crop de segmentation : B, qui mène D de +2,10 IoU sur traffic light et +0,86 sur traffic sign — la région plus propre maintient le classifieur d'état sur les bons pixels.
- Détecteurs d'objets rigides étendus (truck, bus, wall) pour collision et lane-keeping : D, qui mène B de +5,29 sur truck, +2,37 sur bus, +3,73 sur wall.
- Piéton, cycliste et rider : scores essentiellement plats sur A–D dans nos expériences. Le choix de loss ne pèse pas sur ces classes collision-critical. Des techniques orthogonales (focal loss, copy-paste augmentation, oversampling) sont nécessaires.
Pour un pipeline d'entraînement multi-head, la conception actionnable consiste à choisir une loss par head : Dice (ou CE+Dice) sur les heads qui produisent des masques type occupancy, et CE+Boundary sur les heads qui produisent des polylignes ou des contours nets. La variante conjointe C (CE+Dice+Boundary) reste le compromis single-loss sûr pour les modèles single-head — jamais le pire, jamais le meilleur, utile quand des contraintes d'ingénierie excluent la conception loss-par-head.
Le résultat le plus transférable pour une équipe ML VA est méthodologique. Un benchmark de loss à 10 epochs sur Cityscapes décale le gap C−B en mIoU de 2,7 points par rapport à la réponse convergée — suffisant pour inverser une décision production. Les choix de recette de loss pour un module de perception VA doivent être faits sur au moins 80–100 epochs d'entraînement, avec la métrique alignée sur le downstream consommateur plutôt qu'une poursuite générique de mIoU.
7. Conclusion
On propose une ablation 2×2 reproductible de l'espace de design CE / Dice / boundary Kervadec pour la segmentation sémantique pleine résolution sur Cityscapes. À 160 epochs avec 3 seeds par variante, la variante boundary-only D (CE + Kervadec) atteint la plus haute mIoU (81,69 ± 0,12) et le meilleur Boundary F1 (58,67 ± 0,11), tandis que la variante conjointe C — la formulation qu'une étude pilote à 10 epochs aurait choisie — est détrônée à convergence. B (CE + Dice) garde l'avantage sur le Trimap IoU, reflet de sa meilleure cohérence intra-région.
La trouvaille la plus actionnable est méthodologique : les ablations à epochs courts sont systématiquement trompeuses sur cette tâche. Une étude comparant des recettes de loss pour Cityscapes à ≤ 20 epochs inverse le ranking qui tient à 160 epochs. On espère que ce travail découragera les conclusions hâtives sur le choix de loss dans les futurs papiers Cityscapes.
Code, données et reproductibilité
Tout le code, les configs Hydra, le script de génération des figures, les CSV par-epoch des 12 runs et la version Markdown du paper sont disponibles publiquement. Le repo GitHub et la version Zenodo seront mis à jour à la publication.
- Code et données dérivées (GitHub) : guillaume-cassez/city-scape (à publier)
- Archive citable (Zenodo) : DOI à attribuer après publication
- Paper PDF : paper1.pdf (version Markdown compilée)
Cliquez une figure pour l'agrandir
Références
- Chen et al. (2017). Rethinking atrous convolution for semantic image segmentation. arXiv:1706.05587.
- Cheng et al. (2022). Masked-attention mask transformer for universal image segmentation. CVPR.
- Cordts et al. (2016). The Cityscapes dataset for semantic urban scene understanding. CVPR.
- Csurka et al. (2013). What is a good evaluation measure for semantic segmentation ? BMVC.
- Karimi, Salcudean (2019). Reducing the Hausdorff distance in medical image segmentation. IEEE TMI 39(2).
- Kervadec et al. (2019). Boundary loss for highly unbalanced segmentation. MIDL. arXiv:1812.07032.
- Lin et al. (2017). Focal loss for dense object detection. ICCV.
- Long et al. (2015). Fully convolutional networks for semantic segmentation. CVPR.
- Milletari et al. (2016). V-Net: fully convolutional neural networks for volumetric medical image segmentation. 3DV.
- Perazzi et al. (2016). A benchmark dataset and evaluation methodology for video object segmentation. CVPR.
- Sun et al. (2019). High-resolution representations for labeling pixels and regions. arXiv:1904.04514.
- Wang et al. (2022). InternImage : exploring large-scale vision foundation models with deformable convolutions. arXiv:2211.05778.
- Woo et al. (2023). ConvNeXt V2 : co-designing and scaling ConvNets with masked autoencoders. CVPR.
- Xiao et al. (2018). Unified perceptual parsing for scene understanding. ECCV.
- Xie et al. (2021). SegFormer : simple and efficient design for semantic segmentation with transformers. NeurIPS.
À propos de l'auteur
Guillaume Cassez, ingénieur en machine learning et vision par ordinateur. Ce travail s'inscrit dans une série de rapports de recherche indépendants (le précédent porte sur la segmentation de tumeurs cérébrales BraTS 2023).
Actuellement à la recherche d'opportunités : ingénieur ML, recherche appliquée, vision par ordinateur, perception véhicule autonome — CDI, CDD, post-doc industriel ou contrat de mission.
cassez.guillaume@gmail.com · guillaume-cassez.fr · ORCID 0009-0007-0987-3931